
Sparse is Enough in Scaling Transformers (aka Terraformer) | ML Research Paper Explained
#scalingtransformers #terraformer #sparsity
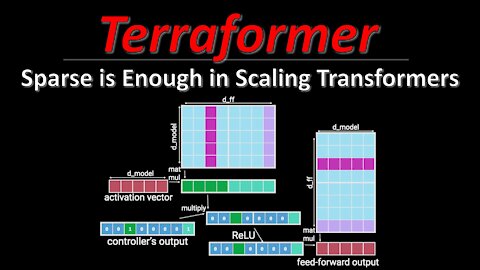
Transformers keep pushing the state of the art in language and other domains, mainly due to their ability to scale to ever more parameters. However, this scaling has made it prohibitively expensive to run a lot of inference requests against a Transformer, both in terms of compute and memory requirements. Scaling Transformers are a new kind of architecture that leverage sparsity in the Transformer blocks to massively speed up inference, and by including additional ideas from other architectures, they create the Terraformer, which is both fast, accurate, and consumes very little memory.
OUTLINE:
0:00 - Intro & Overview
4:10 - Recap: Transformer stack
6:55 - Sparse Feedforward layer
19:20 - Sparse QKV Layer
43:55 - Terraformer architecture
55:05 - Experimental Results & Conclusion
Paper: https://arxiv.org/abs/2111.12763
Code: https://github.com/google/trax/blob/m...
Abstract:
Large Transformer models yield impressive results on many tasks, but are expensive to train, or even fine-tune, and so slow at decoding that their use and study becomes out of reach. We address this problem by leveraging sparsity. We study sparse variants for all layers in the Transformer and propose Scaling Transformers, a family of next generation Transformer models that use sparse layers to scale efficiently and perform unbatched decoding much faster than the standard Transformer as we scale up the model size. Surprisingly, the sparse layers are enough to obtain the same perplexity as the standard Transformer with the same number of parameters. We also integrate with prior sparsity approaches to attention and enable fast inference on long sequences even with limited memory. This results in performance competitive to the state-of-the-art on long text summarization.
Authors: Sebastian Jaszczur, Aakanksha Chowdhery, Afroz Mohiuddin, Łukasz Kaiser, Wojciech Gajewski, Henryk Michalewski, Jonni Kanerva
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
11
views
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning (Paper Explained)
#ext5 #transferlearning #exmix
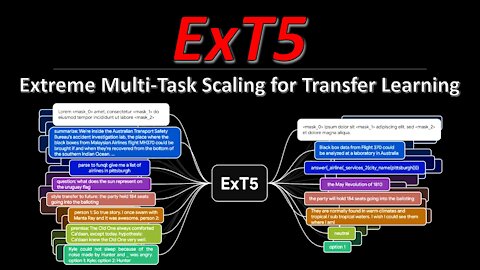
The T5 model has been a staple for NLP research for the last years. Both its size and its approach to formulate all NLP tasks as prompt-based language modeling make it a convenient choice to tackle new challenges and provides a strong baseline for most current datasets. ExT5 pushes T5 to its limits by pre-training not only on self-supervised mask filling, but also at the same time on 107 different supervised NLP tasks, which is their new ExMix dataset. The resulting model compares very favorably to T5 when fine-tuned to downstream tasks.
OUTLINE:
0:00 - Intro & Overview
2:15 - Recap: The T5 model
3:55 - The ExT5 model and task formulations
8:10 - ExMix dataset
9:35 - Do different tasks help each other?
16:50 - Which tasks should we include?
20:30 - Pre-Training vs Pre-Finetuning
23:00 - A few hypotheses about what's going on
27:20 - How much self-supervised data to use?
34:15 - More experimental results
38:40 - Conclusion & Summary
Paper: https://arxiv.org/abs/2111.10952
Abstract:
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
Authors: Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, Donald Metzler
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

Parameter Prediction for Unseen Deep Architectures (w/ First Author Boris Knyazev)
#deeplearning #neuralarchitecturesearch #metalearning
Deep Neural Networks are usually trained from a given parameter initialization using SGD until convergence at a local optimum. This paper goes a different route: Given a novel network architecture for a known dataset, can we predict the final network parameters without ever training them? The authors build a Graph-Hypernetwork and train on a novel dataset of various DNN-architectures to predict high-performing weights. The results show that not only can the GHN predict weights with non-trivial performance, but it can also generalize beyond the distribution of training architectures to predict weights for networks that are much larger, deeper, or wider than ever seen in training.
OUTLINE:
0:00 - Intro & Overview
6:20 - DeepNets-1M Dataset
13:25 - How to train the Hypernetwork
17:30 - Recap on Graph Neural Networks
23:40 - Message Passing mirrors forward and backward propagation
25:20 - How to deal with different output shapes
28:45 - Differentiable Normalization
30:20 - Virtual Residual Edges
34:40 - Meta-Batching
37:00 - Experimental Results
42:00 - Fine-Tuning experiments
45:25 - Public reception of the paper
ERRATA:
- Boris' name is obviously Boris, not Bori
- At 36:05, Boris mentions that they train the first variant, yet on closer examination, we decided it's more like the second
Paper: https://arxiv.org/abs/2110.13100
Code: https://github.com/facebookresearch/p...
Abstract:
Deep learning has been successful in automating the design of features in machine learning pipelines. However, the algorithms optimizing neural network parameters remain largely hand-designed and computationally inefficient. We study if we can use deep learning to directly predict these parameters by exploiting the past knowledge of training other networks. We introduce a large-scale dataset of diverse computational graphs of neural architectures - DeepNets-1M - and use it to explore parameter prediction on CIFAR-10 and ImageNet. By leveraging advances in graph neural networks, we propose a hypernetwork that can predict performant parameters in a single forward pass taking a fraction of a second, even on a CPU. The proposed model achieves surprisingly good performance on unseen and diverse networks. For example, it is able to predict all 24 million parameters of a ResNet-50 achieving a 60% accuracy on CIFAR-10. On ImageNet, top-5 accuracy of some of our networks approaches 50%. Our task along with the model and results can potentially lead to a new, more computationally efficient paradigm of training networks. Our model also learns a strong representation of neural architectures enabling their analysis.
Authors: Boris Knyazev, Michal Drozdzal, Graham W. Taylor, Adriana Romero-Soriano
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
20
views

Peer Review is still BROKEN! The NeurIPS 2021 Review Experiment (results are in)
#neurips #peerreview #machinelearning
A look at the results of the 2021 NeurIPS peer review experiment.
https://arxiv.org/abs/2109.09774
https://www.reddit.com/r/MachineLearn...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
3
views
Learning Rate Grafting: Transferability of Optimizer Tuning (Machine Learning Research Paper Review)
#grafting #adam #sgd
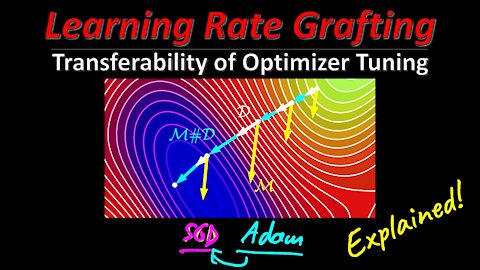
The last years in deep learning research have given rise to a plethora of different optimization algorithms, such as SGD, AdaGrad, Adam, LARS, LAMB, etc. which all claim to have their special peculiarities and advantages. In general, all algorithms modify two major things: The (implicit) learning rate schedule, and a correction to the gradient direction. This paper introduces grafting, which allows to transfer the induced learning rate schedule of one optimizer to another one. In that, the paper shows that much of the benefits of adaptive methods (e.g. Adam) are actually due to this schedule, and not necessarily to the gradient direction correction. Grafting allows for more fundamental research into differences and commonalities between optimizers, and a derived version of it makes it possible to computes static learning rate corrections for SGD, which potentially allows for large savings of GPU memory.
OUTLINE
0:00 - Rant about Reviewer #2
6:25 - Intro & Overview
12:25 - Adaptive Optimization Methods
20:15 - Grafting Algorithm
26:45 - Experimental Results
31:35 - Static Transfer of Learning Rate Ratios
35:25 - Conclusion & Discussion
Paper (OpenReview): https://openreview.net/forum?id=FpKgG...
Old Paper (Arxiv): https://arxiv.org/abs/2002.11803
Our Discord: https://discord.gg/4H8xxDF
Abstract:
In the empirical science of training large neural networks, the learning rate schedule is a notoriously challenging-to-tune hyperparameter, which can depend on all other properties (architecture, optimizer, batch size, dataset, regularization, ...) of the problem. In this work, we probe the entanglements between the optimizer and the learning rate schedule. We propose the technique of optimizer grafting, which allows for the transfer of the overall implicit step size schedule from a tuned optimizer to a new optimizer, preserving empirical performance. This provides a robust plug-and-play baseline for optimizer comparisons, leading to reductions to the computational cost of optimizer hyperparameter search. Using grafting, we discover a non-adaptive learning rate correction to SGD which allows it to train a BERT model to state-of-the-art performance. Besides providing a resource-saving tool for practitioners, the invariances discovered via grafting shed light on the successes and failure modes of optimizers in deep learning.
Authors: Anonymous (Under Review)
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
13
views
![[ML News] Cedille French Language Model | YOU Search Engine | AI Finds Profitable MEME TOKENS](https://hugh.cdn.rumble.cloud/s/s8/1/H/A/a/K/HAaKc.oq1b.2-small-ML-News-Cedille-French-Lang.jpg)
[ML News] Cedille French Language Model | YOU Search Engine | AI Finds Profitable MEME TOKENS
#mlnews #cedille #wmt
Only the greatest of news from the world of Machine Learning.
OUTLINE:
0:00 - Sponsor: Weights & Biases
1:50 - Cedille - French Language Model
3:55 - Facebook AI Multilingual model wins WMT
5:50 - YOU private search engine
10:35 - DeepMind's Open-Source Arnheim
12:10 - Company sued for using AI to make website more accessible
18:05 - Alibaba DAMO Academy creates 10 Trillion M6 model
21:15 - AMD MI200 Family
22:30 - State of AI report 2021
24:15 - Andrew Ng's Landing AI raises 57M
25:40 - Cerebras raises 250M
26:45 - Microsoft's Varuna: Scalable Training of Huge Models
28:15 - Laura Ruis reproduces Extrapolation Paper
29:05 - Ian Charnas' Real-Life Punchout
30:00 - Helpful Things
33:10 - AI finds profitable Meme-Tokens
34:55 - This Sneaker Does Not Exist
Sponsor: Weights & Biases
https://wandb.com
References:
Cedille - French Language Model
https://en.cedille.ai/
https://github.com/coteries/cedille-ai
https://app.cedille.ai/
https://en.wikipedia.org/wiki/Cedilla
Facebook AI Multilingual model wins WMT
https://ai.facebook.com/blog/the-firs...
YOU private search engine
https://you.com/
https://youdotcom.notion.site/FAQ-8c8...
DeepMind's Open-Source Arnheim
https://deepmind.com/research/open-so...
https://twitter.com/OriolVinyalsML/st...
https://github.com/deepmind/arnheim
https://colab.research.google.com/git...
Company sued for using AI to make website more accessible
https://www.wired.com/story/company-t...
https://archive.ph/kdvOM
Alibaba DAMO Academy creates 10 Trillion M6 model
https://pandaily.com/alibaba-damo-aca...
https://www.infoq.cn/article/xIX9leku...
AMD MI200 Family
https://www.anandtech.com/show/17054/...
State of AI report 2021
https://www.stateof.ai/?utm_source=po...
Andrew Ng's Landing AI raises 57M
https://techcrunch.com/2021/11/08/lan...
https://www.forbes.com/sites/bernardm...
https://landing.ai/platform/
Cerebras raises 250M
https://cerebras.net/news/cerebras-sy...
https://cerebras.net/news/cerebras-sy...
Microsoft's Varuna: Scalable Training of Huge Models
https://syncedreview.com/2021/11/10/d...
Laura Ruis reproduces Extrapolation Paper
https://lauraruis.github.io/2021/11/0...
https://github.com/LauraRuis
Ian Charnas' Real-Life Punchout
https://www.reddit.com/r/MachineLearn...
https://www.youtube.com/watch?v=07Jib...
Helpful Things
https://www.marktechpost.com/2021/11/...
https://pair-code.github.io/lit/demos/
https://github.com/pair-code/lit
https://www.reddit.com/r/MachineLearn...
https://twitter.com/yeemachine/status...
https://github.com/yeemachine/kalidokit
AI finds profitable Meme-Tokens
https://finance.yahoo.com/news/artifi...
https://finu.co/
This Sneaker Does Not Exist
https://thissneakerdoesnotexist.com/
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
20
views
Gradients are Not All You Need (Machine Learning Research Paper Explained)
#deeplearning #backpropagation #simulation
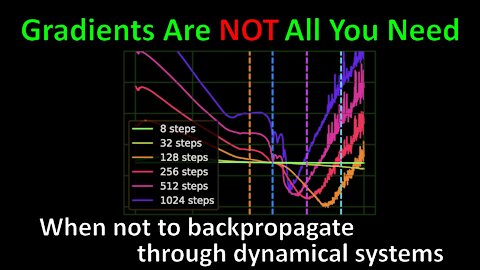
More and more systems are made differentiable, which means that accurate gradients of these systems' dynamics can be computed exactly. While this development has led to a lot of advances, there are also distinct situations where backpropagation can be a very bad idea. This paper characterizes a few such systems in the domain of iterated dynamical systems, often including some source of stochasticity, resulting in chaotic behavior. In these systems, it is often better to use black-box estimators for gradients than computing them exactly.
OUTLINE:
0:00 - Foreword
1:15 - Intro & Overview
3:40 - Backpropagation through iterated systems
12:10 - Connection to the spectrum of the Jacobian
15:35 - The Reparameterization Trick
21:30 - Problems of reparameterization
26:35 - Example 1: Policy Learning in Simulation
33:05 - Example 2: Meta-Learning Optimizers
36:15 - Example 3: Disk packing
37:45 - Analysis of Jacobians
40:20 - What can be done?
45:40 - Just use Black-Box methods
Paper: https://arxiv.org/abs/2111.05803
Abstract:
Differentiable programming techniques are widely used in the community and are responsible for the machine learning renaissance of the past several decades. While these methods are powerful, they have limits. In this short report, we discuss a common chaos based failure mode which appears in a variety of differentiable circumstances, ranging from recurrent neural networks and numerical physics simulation to training learned optimizers. We trace this failure to the spectrum of the Jacobian of the system under study, and provide criteria for when a practitioner might expect this failure to spoil their differentiation based optimization algorithms.
Authors: Luke Metz, C. Daniel Freeman, Samuel S. Schoenholz, Tal Kachman
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
9
views
![[ML News] Microsoft combines Images & Text | Meta makes artificial skin | Russians replicate DALL-E](https://hugh.cdn.rumble.cloud/s/s8/1/D/m/a/K/DmaKc.oq1b.2-small-ML-News-Microsoft-combines-.jpg)
[ML News] Microsoft combines Images & Text | Meta makes artificial skin | Russians replicate DALL-E
#mlnews #turing #reskin
The latest and greatest from the Machine Learning world
OUTLINE:
0:00 - Intro
0:15 - Sponsor: Weights & Biases Tables
3:25 - Microsoft Turing Bletchley: Universal Image Language Representation Model
6:35 - Meta AI Tactile Sensing
9:55 - AnimeGANv2
11:35 - General In-Hand Object Re-Orientation
13:05 - Does Facebook score the "Anger" Emoji too high?
17:05 - IsomorphicLabs: New Alphabet Company for Drug Discovery
18:15 - ruDALL-E: Russian DALL-E
20:40 - Image Scaling Attacks
23:25 - Azure OpenAI Service
24:10 - Neural MMO
25:40 - ArxivDOOM
26:50 - ARC Game
29:35 - ResNeXtGuesser
29:55 - Zillow loses money based on AI home price estimation
31:35 - Helpful Things
35:40 - AI will make your company great! Promise, Human!
Sponsor: Weights & Biases
https://wandb.com
References:
Microsoft Turing Bletchley: Universal Image Language Representation Model
https://www.microsoft.com/en-us/resea...
https://turing.microsoft.com/bletchley
Meta AI Tactile Sensing
https://ai.facebook.com/blog/teaching...
https://ai.facebook.com/blog/reskin-a...
https://twitter.com/AIatMeta/status/1...
AnimeGANv2
https://huggingface.co/spaces/akhaliq...
https://github.com/bryandlee/animegan...
https://github.com/TachibanaYoshino/A...
https://tachibanayoshino.github.io/An...
General In-Hand Object Re-Orientation
https://taochenshh.github.io/projects...
https://arxiv.org/abs/2111.03043
Does Facebook score the "Anger" Emoji too high?
https://www.washingtonpost.com/techno...
IsomorphicLabs: New Alphabet Company for Drug Discovery
https://twitter.com/demishassabis/sta...
https://www.isomorphiclabs.com/blog
ruDALL-E: Russian DALL-E
https://github.com/sberbank-ai/ru-dalle
https://huggingface.co/spaces/anton-l...
https://colab.research.google.com/git...
https://huggingface.co/sberbank-ai/ru...
https://rudalle.ru/
https://habr.com/ru/company/sberbank/...
https://habr-com.translate.goog/ru/co...
Image Scaling Attacks
https://twitter.com/AlexTamkin/status...
https://twitter.com/rzhang88/status/1...
https://arxiv.org/abs/2104.11222
https://twitter.com/arxiv_org/status/...
https://bifold.berlin/preventing-imag...
https://embracethered.com/blog/posts/...
Azure OpenAI Service
https://blogs.microsoft.com/ai/new-az...
https://azure.microsoft.com/en-us/ser...
Neural MMO
https://openai.com/blog/neural-mmo/?u...
https://github.com/jsuarez5341/neural...
https://github.com/jsuarez5341/neural...
https://jsuarez5341.github.io/neural-...
https://jsuarez5341.github.io/neural-...
https://arxiv.org/abs/2110.07594
ArxivDOOM
https://sniklaus.com/arxivdoom?utm_so...
ARC Game
https://github.com/volotat/ARC-Game
https://volotat.github.io/ARC-Game/?
ResNeXtGuesser
https://twitter.com/resnextguesser/st...
Zillow loses money based on AI home price estimation
https://www.reddit.com/r/MachineLearn...
https://www.cbsnews.com/news/zillow-l...
https://www.businessinsider.com/zillo...
https://archive.ph/qEITQ
Helpful Things
https://github.com/PyTorchLightning/p...
https://www.reddit.com/r/MachineLearn...
https://devpost.com/software/iris-7s3yna
https://github.com/prabhuomkar/iris
https://araffin.github.io/post/rliable/
https://github.com/google-research/rl...
https://paperswithcode.com/dataset/me...
AI will make your company great! Promise, Human!
https://fortune.com/2021/11/05/ai-art...
https://sloanreview.mit.edu/projects/...
Patreon: https://www.patreon.com/yannickilcher
6
views
![[ML News] Google introduces Pathways | OpenAI solves Math Problems | Meta goes First Person](https://hugh.cdn.rumble.cloud/s/s8/1/1/3/J/G/13JGc.oq1b.2-small-ML-News-Google-introduces-P.jpg)
[ML News] Google introduces Pathways | OpenAI solves Math Problems | Meta goes First Person
#pathways #mlnews #ego4d
Your irregular dose of Machine Learning News.
OUTLINE:
0:00 - Intro
0:20 - Sponsor: Weights & Biases
2:10 - Google Introduces Pathways AI Architecture
6:30 - OpenAI trains Language Models to do High School Math
8:25 - Sam Altman says Neural Networks truly learn
9:35 - Google AI researchers frustrated with lawyers
12:10 - DeepMind RL Lecture Series 2021
12:40 - Fashion Store sells Adversarial Patches
13:15 - A viable method to remove the GIL from CPython
15:05 - BigScience Workshop releases T0
17:40 - Huggingface Hub Dataset Viewer
18:10 - Scite classifies scientific citations
19:25 - Facebook AI Ego4D dataset & challenges
21:50 - Tesla Dojo Configurable Floating Point Spec
23:10 - Windows releases PyTorch-DirectML for Deep Learning on DirectX GPUs
23:50 - Helpful Things
33:00 - Traders use ML to analyze CEOs' language
34:20 - Cadbury creates DeepFake ads for local Indian businesses
35:25 - This Shoe Does Not Exist
Sponsor: Weights & Biases
https://wandb.com
References:
Google Introduces Pathways AI Architecture
https://blog.google/technology/ai/int...
OpenAI trains Language Models to do High School Math
https://openai.com/blog/grade-school-...
https://arxiv.org/abs/2110.14168
Sam Altman says Neural Networks truly learn
https://twitter.com/sama/status/14508...
Google AI researchers frustrated with lawyers
https://archive.ph/lsQJJ#selection-28...
DeepMind RL Lecture Series 2021
https://deepmind.com/learning-resourc...
Fashion Store sells Adversarial Patches
https://twitter.com/naotokui/status/1...
A viable method to remove the GIL from CPython
https://lwn.net/Articles/872869/
BigScience Workshop releases T0
https://bigscience.huggingface.co/
https://arxiv.org/abs/2110.08207
https://huggingface.co/bigscience/T0pp
Huggingface Hub Dataset Viewer
https://twitter.com/huggingface/statu...
Scite classifies scientific citations
https://scite.ai
https://direct.mit.edu/qss/article/do...
Facebook AI Ego4D dataset & challenges
https://ai.facebook.com/blog/teaching...
Tesla Dojo Configurable Floating Point Spec
https://tesla-cdn.thron.com/static/SB...
Windows releases PyTorch-DirectML for Deep Learning on DirectX GPUs
https://devblogs.microsoft.com/window...
Helpful Things
https://github.com/achaiah/pywick?utm...
https://github.com/orybkin/lexa-bench...
https://orybkin.github.io/lexa/
https://twitter.com/danijarh/status/1...
https://github.com/RobertTLange/mle-h...
https://keras.io/examples/vision/mobi...
https://twitter.com/osanseviero/statu...
https://huggingface.co/spaces/flax-co...
https://huggingface.co/transformers/m...
https://github.com/facebookresearch/b...
https://arxiv.org/abs/2110.11216
https://arxiv.org/pdf/2110.11216.pdf
https://github.com/facebookresearch/x...
https://superbbenchmark.org/
https://arxiv.org/abs/2110.07731
https://github.com/BaguaSys/bagua?utm...
https://github.com/cgarciae/treex
https://jax.readthedocs.io/en/latest/...
Traders use ML to analyze CEOs' language
https://www.reuters.com/technology/ai...
Cadbury creates DeepFake ads for local Indian businesses
https://www.bgr.in/entertainment/shah...
This Shoe Does Not Exist
https://www.thisshoedoesnotexist.com/
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
55
views
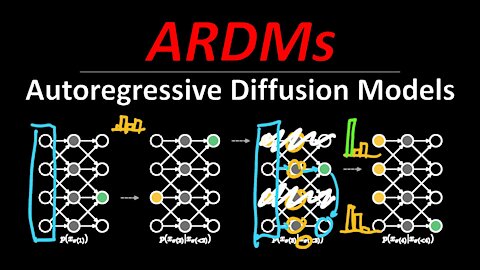
Autoregressive Diffusion Models (Machine Learning Research Paper Explained)
#machinelearning #ardm #generativemodels
Diffusion models have made large advances in recent months as a new type of generative models. This paper introduces Autoregressive Diffusion Models (ARDMs), which are a mix between autoregressive generative models and diffusion models. ARDMs are trained to be agnostic to the order of autoregressive decoding and give the user a dynamic tradeoff between speed and performance at decoding time. This paper applies ARDMs to both text and image data, and as an extension, the models can also be used to perform lossless compression.
OUTLINE:
0:00 - Intro & Overview
3:15 - Decoding Order in Autoregressive Models
6:15 - Autoregressive Diffusion Models
8:35 - Dependent and Independent Sampling
14:25 - Application to Character-Level Language Models
18:15 - How Sampling & Training Works
26:05 - Extension 1: Parallel Sampling
29:20 - Extension 2: Depth Upscaling
33:10 - Conclusion & Comments
Paper: https://arxiv.org/abs/2110.02037
Abstract:
We introduce Autoregressive Diffusion Models (ARDMs), a model class encompassing and generalizing order-agnostic autoregressive models (Uria et al., 2014) and absorbing discrete diffusion (Austin et al., 2021), which we show are special cases of ARDMs under mild assumptions. ARDMs are simple to implement and easy to train. Unlike standard ARMs, they do not require causal masking of model representations, and can be trained using an efficient objective similar to modern probabilistic diffusion models that scales favourably to highly-dimensional data. At test time, ARDMs support parallel generation which can be adapted to fit any given generation budget. We find that ARDMs require significantly fewer steps than discrete diffusion models to attain the same performance. Finally, we apply ARDMs to lossless compression, and show that they are uniquely suited to this task. Contrary to existing approaches based on bits-back coding, ARDMs obtain compelling results not only on complete datasets, but also on compressing single data points. Moreover, this can be done using a modest number of network calls for (de)compression due to the model's adaptable parallel generation.
Authors: Emiel Hoogeboom, Alexey A. Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, Tim Salimans
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
127
views
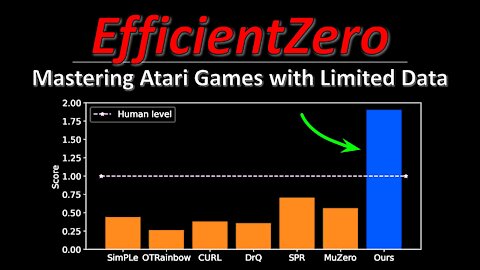
EfficientZero: Mastering Atari Games with Limited Data (Machine Learning Research Paper Explained)
#efficientzero #muzero #atari
Reinforcement Learning methods are notoriously data-hungry. Notably, MuZero learns a latent world model just from scalar feedback of reward- and policy-predictions, and therefore relies on scale to perform well. However, most RL algorithms fail when presented with very little data. EfficientZero makes several improvements over MuZero that allows it to learn from astonishingly small amounts of data and outperform other methods by a large margin in the low-sample setting. This could be a staple algorithm for future RL research.
OUTLINE:
0:00 - Intro & Outline
2:30 - MuZero Recap
10:50 - EfficientZero improvements
14:15 - Self-Supervised consistency loss
17:50 - End-to-end prediction of the value prefix
20:40 - Model-based off-policy correction
25:45 - Experimental Results & Conclusion
Paper: https://arxiv.org/abs/2111.00210
Code: https://github.com/YeWR/EfficientZero
Note: code not there yet as of release of this video
Abstract:
Reinforcement learning has achieved great success in many applications. However, sample efficiency remains a key challenge, with prominent methods requiring millions (or even billions) of environment steps to train. Recently, there has been significant progress in sample efficient image-based RL algorithms; however, consistent human-level performance on the Atari game benchmark remains an elusive goal. We propose a sample efficient model-based visual RL algorithm built on MuZero, which we name EfficientZero. Our method achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperforms the state SAC in some tasks on the DMControl 100k benchmark. This is the first time an algorithm achieves super-human performance on Atari games with such little data. EfficientZero's performance is also close to DQN's performance at 200 million frames while we consume 500 times less data. EfficientZero's low sample complexity and high performance can bring RL closer to real-world applicability. We implement our algorithm in an easy-to-understand manner and it is available at this https URL. We hope it will accelerate the research of MCTS-based RL algorithms in the wider community.
Authors: Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, Yang Gao
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
12
views
![[YTalks] Siraj Raval - Stories about YouTube, Plagiarism, and the Dangers of Fame (Interview)](https://hugh.cdn.rumble.cloud/s/s8/1/Z/q/z/D/ZqzDc.oq1b.2-small-YTalks-Siraj-Raval-Stories-.jpg)
[YTalks] Siraj Raval - Stories about YouTube, Plagiarism, and the Dangers of Fame (Interview)
#ytalks #siraj #plagiarism
A conversation with Siraj Raval about his journey on YouTube, and the perils of fame.
OUTLINE:
0:00 - Intro
1:30 - Welcome
3:15 - Starting out: From Economics to YouTube
13:00 - More Views: Plagiarizing Video Content
23:30 - One Step Up: Copying A Research Paper
29:15 - Was there another way?
39:00 - Clickbait Course: Make Money with Machine Learning
50:30 - Rock Bottom and the Way Forward
1:01:30 - Advice for Future Generations
Siraj's Channel: https://www.youtube.com/c/SirajRaval
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
16
views
2
comments
![[ML News] NVIDIA GTC'21 | DeepMind buys MuJoCo | Google predicts spreadsheet formulas](https://hugh.cdn.rumble.cloud/s/s8/1/_/-/y/D/_-yDc.oq1b.2-small-ML-News-NVIDIA-GTC21-DeepMi.jpg)
[ML News] NVIDIA GTC'21 | DeepMind buys MuJoCo | Google predicts spreadsheet formulas
#gtc21 #mlnews #mujoco
Register to GTC'21 and Win a RTX 3090: https://nvda.ws/2Y2B5ni
OUTLINE:
0:00 - Intro
0:15 - Sponsor: NVIDIA GTC'21
5:35 - DeepMind buys & Open-Sources MuJoCo
7:25 - PyTorch 1.10 Released
9:10 - Google Predicts Spreadsheet Formulas
11:25 - handtracking.io
12:25 - Cell Instance Segmentation Challenge
13:00 - Helpful Libraries
17:50 - Waymo cars keep turning into same dead-end
19:35 - BlueRiver balances tractors
References:
DeepMind buys & open-sources MuJoCo
https://deepmind.com/blog/announcemen...
PyTorch 1.10 released
https://pytorch.org/blog/pytorch-1.10...
https://developer.nvidia.com/blog/cud...
GoogleAI predicts spreadsheet formulas
https://ai.googleblog.com/2021/10/pre...
Handtracking in Browser
https://handtracking.io/
https://handtracking.io/draw_demo/
Sartorius Cell Instance Segmentation Competition
https://www.kaggle.com/c/sartorius-ce...
Helpful Libraries
https://github.com/IntelLabs/control-...
https://github.com/facebookresearch/s...
https://github.com/facebookresearch/s...
https://github.com/ydataai/ydata-synt...
https://syntheticdata.community/
https://github.com/ydataai/ydata-synt...
https://medium.com/aimstack/aim-3-0-0...
https://github.com/aimhubio/aim
https://robustbench.github.io/
Waymo cars keep coming to same dead-end over and over
https://sanfrancisco.cbslocal.com/202...
BlueRiver balances tractors
https://www.linkedin.com/posts/lredde...
https://bluerivertechnology.com/ourme...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
19
views
![[ML News GERMAN] NVIDIA GTC'21 | DeepMind kauft MuJoCo | Google Lernt Spreadsheet Formeln](https://hugh.cdn.rumble.cloud/s/s8/1/L/h/z/D/LhzDc.oq1b.2-small-ML-News-GERMAN-NVIDIA-GTC21.jpg)
[ML News GERMAN] NVIDIA GTC'21 | DeepMind kauft MuJoCo | Google Lernt Spreadsheet Formeln
#gtc21 #mlnews #mujoco
Registriere für GTC'21 und gewinne eine RTX 3090: https://nvda.ws/2Y2B5ni
OUTLINE:
0:00 - Intro
0:15 - Sponsor: NVIDIA GTC'21
6:10 - DeepMind kauft & Open-Sourct MuJoCo
9:05 - PyTorch 1.10 Veröffentlicht
11:25 - Google Lernt Spreadsheet Formeln
14:15 - handtracking.io
15:25 - Zellinstanzsegmentierungswettbewerb
16:15 - Hilfreiche Bibliotheken
23:15 - Waymo autos verirren sich alle in der selben Sackgasse
24:50 - BlueRiver balanciert Traktoren
References:
DeepMind kauft & open-sourct MuJoCo
https://deepmind.com/blog/announcemen...
PyTorch 1.10 veröffentlicht
https://pytorch.org/blog/pytorch-1.10...
https://developer.nvidia.com/blog/cud...
GoogleAI sagt Tabellen-Formeln voraus
https://ai.googleblog.com/2021/10/pre...
Handtracking im Browser
https://handtracking.io/
https://handtracking.io/draw_demo/
Sartorius Zellinstanzsegmentierungswettbewerb
https://www.kaggle.com/c/sartorius-ce...
Hilfreiche Bibliotheken
https://github.com/IntelLabs/control-...
https://github.com/facebookresearch/s...
https://github.com/facebookresearch/s...
https://github.com/ydataai/ydata-synt...
https://syntheticdata.community/
https://github.com/ydataai/ydata-synt...
https://medium.com/aimstack/aim-3-0-0...
https://github.com/aimhubio/aim
https://robustbench.github.io/
Waymo Autos verirren sich in dieselbe Sackgasse wieder und wieder
https://sanfrancisco.cbslocal.com/202...
BlueRiver balanciert Traktoren
https://www.linkedin.com/posts/lredde...
https://bluerivertechnology.com/ourme...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

I went to an AI Art Festival in Geneva (AiiA Festival Trip Report)
#aiia #ai #art
A trip report from the AiiA Festival in Geneva organized by the ImpactAI foundation.
OUTLINE:
0:00 - Intro
1:50 - Laura Tocmacov: The Festival
4:10 - Timothy O'Hear: The Tech
6:50 - Jonathan O'Hear: The Robot
11:50 - Cléa Chopard: The Artist
17:45 - Final Words
Website: https://aiiafestival.org/en/
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views

Symbolic Knowledge Distillation: from General Language Models to Commonsense Models (Explained)
#gpt3 #knowledge #symbolic
Symbolic knowledge models are usually trained on human-generated corpora that are cumbersome and expensive to create. Such corpora consist of structured triples of symbolic knowledge. This paper takes a different approach and attempts to generate such a corpus by prompting GPT-3. Results show that clever prompting, combined with targeted small critic models trained on human ratings can outperform both human-generated data, as well as the teacher model (GPT-3) itself. The results of this paper give a general recipe for automatically building corpora for various NLP tasks by extracting samples from large language models.
OUTLINE:
0:00 - Intro & Overview
2:30 - Sponsor: Weights & Biases
4:15 - Commonsense Knowledge Graphs
7:50 - ATOMIC dataset
10:00 - Generating the corpus from a model
13:00 - Prompting GPT-3
15:30 - Generating Events
18:40 - Generating Inferences
23:00 - Evaluating the created dataset
26:45 - Introducing the critic
31:25 - Using the critic to filter the data
36:30 - Training a student on the generated data
41:00 - Key Findings
44:45 - Comments & Conclusion
Paper: https://arxiv.org/abs/2110.07178
Code & Corpus: https://github.com/peterwestai2/symbo...
Sponsor: Weights & Biases
https://wandb.com
https://community.wandb.ai/
Abstract:
The common practice for training commonsense models has gone from-human-to-corpus-to-machine: humans author commonsense knowledge graphs in order to train commonsense models. In this work, we investigate an alternative, from-machine-to-corpus-to-machine: general language models author these commonsense knowledge graphs to train commonsense models. Our study leads to a new framework, Symbolic Knowledge Distillation. As with prior art in Knowledge Distillation (Hinton et al., 2015), our approach uses larger models to teach smaller models. A key difference is that we distill knowledge symbolically-as text-in addition to the neural model. We also distill only one aspect-the commonsense of a general language model teacher, allowing the student to be a different type, a commonsense model. Altogether, we show that careful prompt engineering and a separately trained critic model allow us to selectively distill high-quality causal commonsense from GPT-3, a general language model. Empirical results demonstrate that, for the first time, a human-authored commonsense knowledge graph is surpassed by our automatically distilled variant in all three criteria: quantity, quality, and diversity. In addition, it results in a neural commonsense model that surpasses the teacher model's commonsense capabilities despite its 100x smaller size. We apply this to the ATOMIC resource, and share our new symbolic knowledge graph and commonsense models.
Authors: Peter West, Chandra Bhagavatula, Jack Hessel, Jena D. Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, Yejin Choi
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
524
views

I took a Swiss train and it was awesome! Train Seat Review - SBB InterCity 1 - Geneva to St. Gallen
#sbb #seatreview #travel
A friendly parody of Travel Vloggers and Airplane Seat Reviews :)
No, SBB did not pay me for this (but they should ;) )
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
3
views
![[ML News] Microsoft trains 530B model | ConvMixer model fits into single tweet | DeepMind profitable](https://hugh.cdn.rumble.cloud/s/s8/1/b/6/4/z/b64zc.oq1b.2-small-ML-News-Microsoft-trains-53.jpg)
[ML News] Microsoft trains 530B model | ConvMixer model fits into single tweet | DeepMind profitable
#mlnews #turingnlg #convmixer
Your latest upates on what's happening in the Machine Learning world.
OUTLINE:
0:00 - Intro
0:16 - Weights & Biases raises on 1B valuation (sponsored)
2:30 - Microsoft trains 530 billion parameter model
5:15 - StyleGAN v3 released
6:45 - A few more examples may be worth billions of parameters
8:30 - ConvMixer fits into a tweet
9:45 - Improved VQGAN
11:25 - William Shatner AI chats about his life
12:35 - Google AI pushes material science
14:10 - Gretel AI raises 50M for privacy protection
16:05 - DeepMind's push into ML for biology
19:00 - Schmidhuber laudates Kunihiko Fukushima for Bower Award
21:30 - Helpful Things
22:25 - Mosaic ML out of stealth mode
23:55 - First German self-driving train
24:45 - Ex-Pentagon Chief: China has already won
26:25 - DeepMind becomes profitable
Sponsor: Weights & Biases
https://wandb.com
References:
Microsoft Trains 530B Parameter Model
https://www.microsoft.com/en-us/resea...
StyleGAN 3 Code Released
https://nvlabs.github.io/stylegan3/
https://github.com/NVlabs/stylegan3
https://colab.research.google.com/git...
When do labels help?
https://arxiv.org/pdf/2110.04374.pdf
ml_paper.bruh
https://openreview.net/pdf?id=TVHS5Y4...
Improved VQGAN
https://openreview.net/pdf?id=pfNyExj7z2
William Shatner "AI" & Storyfile
https://www.livescience.com/william-s...
https://www.storyfile.com/
GoogleAI Finds Complex Metal Oxides
https://ai.googleblog.com/2021/10/fin...
GretelAI raises 50M Series B
https://techcrunch.com/2021/10/07/gre...
https://gretel.ai/
https://gretel.ai/blog/why-privacy-by...
DeepMind's Push in ML for Bio
https://www.biorxiv.org/content/10.11...
https://deepmind.com/blog/article/enf...
Kunihiko Fukushima wins Bower Award: Schmidhuber Congratulates
https://www.fi.edu/laureates/kunihiko...
https://www.youtube.com/watch?v=ysOw6...
Helpful Things
https://github.com/UKPLab/beir#beers-...
https://arxiv.org/pdf/2104.08663.pdf
https://bayesoptbook.com/
https://github.com/nvlabs/imaginaire/
https://github.com/NVlabs/imaginaire/...
MosaicML out of Stealth Mode
https://www.mosaicml.com/
https://www.mosaicml.com/blog/founder...
https://app.mosaicml.com/library/imag...
https://github.com/mosaicml/composer
https://mosaicml-composer.readthedocs...
Germany's first self-driving train
https://techxplore.com/news/2021-10-g...
Ex-Pentagon Chief: China has already won tech war
https://nypost.com/2021/10/11/pentago...
DeepMind becomes profitable
https://bdtechtalks.com/2021/10/07/go...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
111
views
![[ML News] DeepMind does Nowcasting | The Guardian's shady reporting | AI finishes Beethoven's 10th](https://hugh.cdn.rumble.cloud/s/s8/1/9/9/o/x/99oxc.oq1b.2-small-ML-News-DeepMind-does-Nowca.jpg)
[ML News] DeepMind does Nowcasting | The Guardian's shady reporting | AI finishes Beethoven's 10th
#deepmind #nowcasting #machinelearning
Your holy update on what's new in the Machine Learning world.
OUTLINE:
0:00 - Intro
0:30 - DeepMind tackles Nowcasting
3:30 - The Guardian's shady reporting on TruthfulQA
6:15 - Stochastic training not necessary for generalization
7:35 - Google AI's efficient partitioning of road networks
9:15 - MiniHack Reinforcement Learning Environment
10:45 - Plato XL 11B dialog model
11:35 - AI finishes Beethoven's 10th Symphony
13:10 - AI casts doubt on painting authenticity
15:55 - ShadowDragon social media surveillance
18:45 - Helpful Libraries
25:20 - Samsung to copy-paste brains onto chips
References:
DeepMind improves Nowcasting
https://deepmind.com/blog/article/now...
https://www.nature.com/articles/s4158...
https://github.com/deepmind/deepmind-...
https://colab.research.google.com/git...
The Guardian's shady reporting on TruthfulQA
https://www.theguardian.com/commentis...
Stochastic Training is Not Necessary for Generalization
https://arxiv.org/pdf/2109.14119.pdf
Google AI - Efficient Partitioning of Road Networks
https://ai.googleblog.com/2021/09/eff...
MiniHack Reinforcement Learning Environment
https://ai.facebook.com/blog/minihack...
Baidu PLATO-XL 11B Dialog Model
http://research.baidu.com/Blog/index-...
AI finishes Beethoven's 10th Symphony
https://thenextweb.com/news/computer-...
AI casts doubt on paining authenticity
https://www.smithsonianmag.com/smart-...
https://art-recognition.com/
https://art-recognition.com/case-stud...
https://art-recognition.com/faq/
ShadowDragon Social Media Surveillance
https://www.rt.com/usa/535630-ai-surv...
https://theintercept.com/2021/09/21/s...
Helpful Libraries / Datasets
https://huggingface.co/infinity
https://yanaiela.github.io/TNE/?s=09&...
https://arxiv.org/abs/2109.10282
https://github.com/microsoft/unilm/tr...
https://medium.com/people-ai-research...
https://raft.elicit.org/
https://huggingface.co/spaces/ought/r...
https://huggingface.co/spaces/ought/r...
https://arxiv.org/pdf/2109.14076.pdf
https://arxiv.org/pdf/2109.14394.pdf
https://www.robots.ox.ac.uk/~vgg/rese...
https://zenodo.org/record/5528345#.YV...
https://github.com/yukimasano/PASS/
https://openreview.net/pdf?id=BwzYI-K...
https://github.com/pytorch/data?utm_s...
Samsung Method to copy paste brain onto chip
https://www.engadget.com/samsung-copy...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
30
views
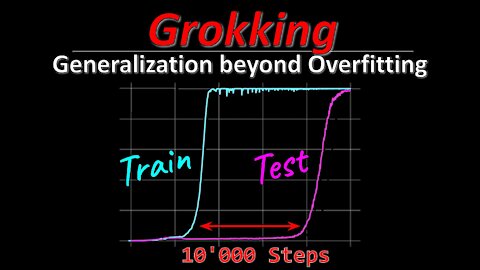
Grokking: Generalization beyond Overfitting on small algorithmic datasets (Paper Explained)
#grokking #openai #deeplearning
Grokking is a phenomenon when a neural network suddenly learns a pattern in the dataset and jumps from random chance generalization to perfect generalization very suddenly. This paper demonstrates grokking on small algorithmic datasets where a network has to fill in binary tables. Interestingly, the learned latent spaces show an emergence of the underlying binary operations that the data were created with.
OUTLINE:
0:00 - Intro & Overview
1:40 - The Grokking Phenomenon
3:50 - Related: Double Descent
7:50 - Binary Operations Datasets
11:45 - What quantities influence grokking?
15:40 - Learned Emerging Structure
17:35 - The role of smoothness
21:30 - Simple explanations win
24:30 - Why does weight decay encourage simplicity?
26:40 - Appendix
28:55 - Conclusion & Comments
Paper: https://mathai-iclr.github.io/papers/...
Abstract:
In this paper we propose to study generalization of neural networks on small algorithmically generated datasets. In this setting, questions about data efficiency, memorization, generalization, and speed of learning can be studied in great detail. In some situations we show that neural networks learn through a process of “grokking” a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in generalization can happen well past the point of overfitting. We also study generalization as a function of dataset size and find that smaller datasets require increasing amounts of optimization for generalization. We argue that these datasets provide a fertile ground for studying a poorly understood aspect of deep learning: generalization of overparametrized neural networks beyond memorization of the finite training dataset.
Authors: Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin & Vedant Misra
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
17
views

How far can we scale up? Deep Learning's Diminishing Returns (Article Review)
#deeplearning #co2 #cost
Deep Learning has achieved impressive results in the last years, not least due to the massive increases in computational power and data that has gone into these models. Scaling up currently promises to be a reliable way to create more performant systems, but how far can we go? This article explores the limits of exponential scaling in AI, and what people are doing to get around this problem
OUTLINE:
0:00 - Intro & Overview
1:00 - Deep Learning at its limits
3:10 - The cost of overparameterization
5:40 - Extrapolating power usage and CO2 emissions
10:45 - We cannot just continue scaling up
13:25 - Current solution attempts
15:25 - Aside: ImageNet V2
17:50 - Are symbolic methods the way out?
Paper: https://spectrum.ieee.org/deep-learni...
Image by Ralf Vetterle from Pixabay: https://pixabay.com/images/id-1752876/
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
5
views
![[ML News] Plagiarism Case w/ Plot Twist | CLIP for video surveillance | OpenAI summarizes books](https://hugh.cdn.rumble.cloud/s/s8/1/d/U/D/u/dUDuc.oq1b.2-small-ML-News-Plagiarism-Case-w-P.jpg)
[ML News] Plagiarism Case w/ Plot Twist | CLIP for video surveillance | OpenAI summarizes books
#plagiarism #surveillance #schmidhuber
Your Mondaily updates of what's going in the world of Machine Learning.
OUTLINE:
0:00 - Intro
0:20 - New plagiarism case has plot twist
7:25 - CLIP for video surveillance
9:40 - DARPA SubTerranean Challenge
11:00 - Schmidhuber criticizing Turing Lecture
15:00 - OpenAI summarizes books
17:55 - UnBiasIt monitors employees' communications for bias
20:00 - iOS plans to detect depression
21:30 - UK 10 year plan to become AI superpower
23:30 - Helpful Libraries
29:00 - WIT: Wikipedia Image-Text dataset
References:
New plagiarism case with plot twist
https://www.reddit.com/r/MachineLearn...
https://zhuanlan.zhihu.com/p/411800486
https://github.com/cybercore-co-ltd/C...
CLIP used for video surveillance
https://www.reddit.com/r/MachineLearn...
https://github.com/johanmodin/clifs
DARPA SubTerranean Challenge
https://twitter.com/BotJunkie/status/...
https://twitter.com/BotJunkie
https://www.subtchallenge.com/index.html
https://www.subtchallenge.com/resourc...
https://twitter.com/dynamicrobots/sta...
Schmidhuber Blog: Turing Lecture Errors
https://people.idsia.ch/~juergen/scie...
OpenAI on Summarizing Books
https://openai.com/blog/summarizing-b...
https://arxiv.org/pdf/2109.10862.pdf
UnBiasIt to monitor employee language
https://edition.cnn.com/2021/09/20/te...
https://www.unbiasit.com/
iPhone to detect depression
https://www.wsj.com/articles/apple-wa...
https://archive.ph/hRTnw
UK 10-year plan to become AI-superpower
https://www.cnbc.com/2021/09/22/uk-pu...
https://archive.ph/4gkKK
Helpful Libraries
https://twitter.com/scikit_learn/stat...
https://scikit-learn.org/stable/auto_...
https://twitter.com/pcastr/status/144...
https://github.com/google/dopamine
https://github.com/microsoft/muzic
https://ai-muzic.github.io/muzic_logo/
https://ai.facebook.com/blog/dynatask...
https://github.com/tum-pbs/PhiFlow
https://github.com/facebookresearch/dora
Habitat and Matterport 3D Dataset
https://github.com/facebookresearch/h...
https://aihabitat.org/
https://arxiv.org/pdf/2109.08238.pdf
WIT: Wikipedia-Based Image-Text Dataset
https://ai.googleblog.com/2021/09/ann...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
28
views

Inconsistency in Conference Peer Review: Revisiting the 2014 NeurIPS Experiment (Paper Explained)
#neurips #peerreview #nips
The peer-review system at Machine Learning conferences has come under much criticism over the last years. One major driver was the infamous 2014 NeurIPS experiment, where a subset of papers were given to two different sets of reviewers. This experiment showed that only about half of all accepted papers were consistently accepted by both committees and demonstrated significant influence of subjectivity. This paper revisits the data from the 2014 experiment and traces the fate of accepted and rejected papers during the 7 years since, and analyzes how well reviewers can assess future impact, among other things.
OUTLINE:
0:00 - Intro & Overview
1:20 - Recap: The 2014 NeurIPS Experiment
5:40 - How much of reviewing is subjective?
11:00 - Validation via simulation
15:45 - Can reviewers predict future impact?
23:10 - Discussion & Comments
Paper: https://arxiv.org/abs/2109.09774
Code: https://github.com/lawrennd/neurips2014/
Abstract:
In this paper we revisit the 2014 NeurIPS experiment that examined inconsistency in conference peer review. We determine that 50% of the variation in reviewer quality scores was subjective in origin. Further, with seven years passing since the experiment we find that for accepted papers, there is no correlation between quality scores and impact of the paper as measured as a function of citation count. We trace the fate of rejected papers, recovering where these papers were eventually published. For these papers we find a correlation between quality scores and impact. We conclude that the reviewing process for the 2014 conference was good for identifying poor papers, but poor for identifying good papers. We give some suggestions for improving the reviewing process but also warn against removing the subjective element. Finally, we suggest that the real conclusion of the experiment is that the community should place less onus on the notion of top-tier conference publications when assessing the quality of individual researchers. For NeurIPS 2021, the PCs are repeating the experiment, as well as conducting new ones.
Authors: Corinna Cortes, Neil D. Lawrence
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
39
views
![[ML News] New ImageNet SOTA | Uber's H3 hexagonal coordinate system | New text-image-pair dataset](https://hugh.cdn.rumble.cloud/s/s8/1/v/B/Z/t/vBZtc.oq1b.2-small-ML-News-New-ImageNet-SOTA-U.jpg)
[ML News] New ImageNet SOTA | Uber's H3 hexagonal coordinate system | New text-image-pair dataset
#truthfulqa #efficientnet #laion400M
Your regularly irregular updates on what's happening in the Machine Learning world.
OUTLINE:
0:00 - Intro
0:20 - TruthfulQA benchmark shines new light on GPT-3
2:00 - LAION-400M image-text-pair dataset
4:10 - GoogleAI's EfficientNetV2 and CoAtNet
6:15 - Uber's H3: A hexagonal coordinate system
7:40 - AWS NeurIPS 2021 DeepRacer Challenge
8:15 - Helpful Libraries
9:20 - State of PyTorch in September 2021
10:05 - Physics-Based Deep Learning Book
10:35 - Music-conditioned 3D dance generation
11:40 - Stallman's take on legal issues with Codex
12:20 - Tensorflow DirectML on AMD GPUs
13:00 - Schmidhuber Blog: Turing Oversold
ERRATA:
Uber's H3 is actually not new, but from 2018
References:
TruthfulQA - A benchmark assessing truthfulness of language models
https://owainevans.github.io/pdfs/tru...
LAION-400M image-text-pair dataset
https://laion.ai/laion-400-open-dataset/
https://laion.ai/#top
https://gogetfunding.com/help-us-buil...
https://rom1504.github.io/clip-retrie...
GooleAI releases EfficientNetV2 and CoAtNet
https://ai.googleblog.com/2021/09/tow...
Uber's H3 hexagonal coordinate systems
https://eng.uber.com/h3/?utm_source=p...
NeurIPS 2021 DeepRacer Challenge
https://www.aicrowd.com/challenges/ne...
https://aws.amazon.com/deepracer/
https://gitlab.aicrowd.com/deepracer/...
Helpful Libraries
https://github.com/rom1504/img2dataset
https://github.com/facebookresearch/v...
https://github.com/pyg-team/pytorch_g...
https://aws.amazon.com/blogs/machine-...
State of PyTorch in September 2021
https://dev-discuss.pytorch.org/t/sta...
Physics-Based Deep Learning Book
http://physicsbaseddeeplearning.org/i...
https://arxiv.org/pdf/2109.05237.pdf
Music Conditioned 3D dance generation
https://ai.googleblog.com/2021/09/mus...
Richard Stallman on Codex legal issues
https://news.slashdot.org/story/21/09...
Tensorflow DirectML on AMD
https://wccftech.com/amd-microsoft-br...
Schmidhuber: Turing Oversold
https://people.idsia.ch//~juergen/tur...
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
63
views
Does GPT-3 lie? - Misinformation and fear-mongering around the TruthfulQA dataset
#gpt-3 #truth #conspiracy
A new benchmark paper has created quite an uproar in the community. TruthfulQA is a dataset of 817 questions probing for imitative falsehoods where language models become less truthful, the larger they get. This surprising counter-intuitive finding validates many people's criticisms of large language models, but is it really the correct conclusion?
OUTLINE:
0:00 - Intro
0:30 - Twitter Paper Announcement
4:10 - Large Language Models are to blame!
5:50 - How was the dataset constructed?
9:25 - The questions are adversarial
12:30 - Are you surprised?!
Paper: https://arxiv.org/abs/2109.07958
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
4
views