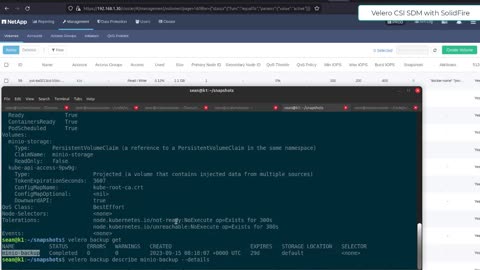
Velero CSI Snapshot Data Mover with NetApp Trident and SolidFire
This feature performs incremental "direct backup to S3" with the advantage of doing it off a CSI volume cloned from a CSI snapshot.
So rather than copying files one by one (while they change) off a live volume using Kopia or Restic, this thing snaps the PV, clones the volume and backs it up to S3.
More here:
https://scaleoutsean.github.io/2023/09/15/velero-csi-snapshot-data-movement-with-netapp-solidfire.html
13
views
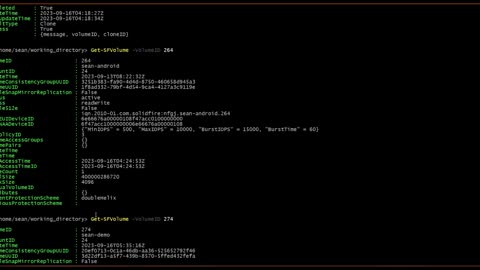
SolidFire Volume Clone Demo
Just a quick demo of creating a volume clone from a volume with 143G of Android source code data.
Some platforms may be able to create clones faster, but they may suffer from contention. In the case of SolidFire they do not suffer from contention.
More here:
https://scaleoutsean.github.io/2023/08/30/monitoring-solidfire-clone-and-backup-jobs.html
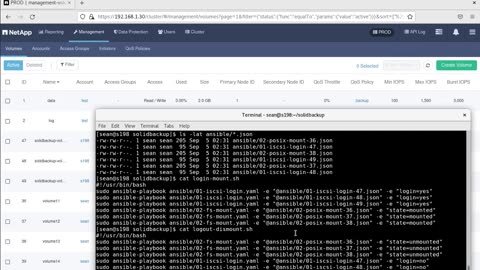
SolidBackup with Kopia
Use SolidBackup scripts to clone and sync volumes and make them available to a "backup VM" which also has Kopia installed.
Then, with these cloned volumes that need a backup accessible in this VM, define and run Kopia backup jobs to backup data to S3 or B2.
This may be suitable for department scale environments where different application owners can give the administrator access to their data for data protection purposes. The entire process is administrator-managed, there are no user-managed steps.
Additional details:
https://scaleoutsean.github.io/2023/09/03/solidbackup-with-kopia.html
8
views
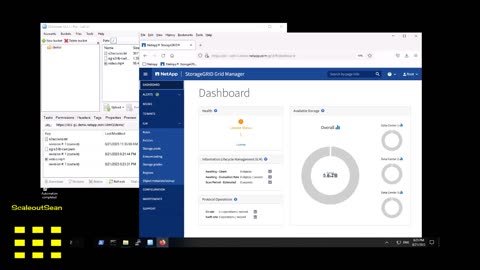
Example of using per-site and Erasure Coding rules and ILM policies
I use StorageGRID 11.7 to illustrate how to change the default StorageGRID "2 copies (on randomly selected storage nodes)" ILM rule to custom "1 copy per site DC1 and DC2 with EC for larger objects".
On the one hand that takes one minute to do, on the other you don't want to do it wrong and there's usually some additional rule or rules that people want, so don't do this on production storage without RTFM and even testing in the lab.
1
view
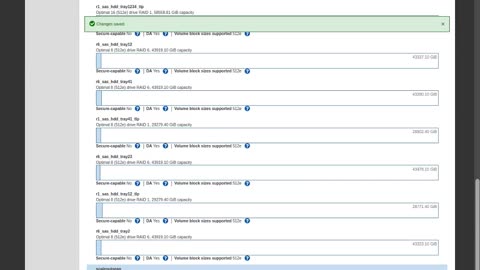
Expand E-Series DPP (pool) and grow and shrink its preservation capacity
DPP (pools) can grow by 1 or more disks of the same (or larger) size and identical type.
A pool's preservation capacity (aka reserve) can be increased or decreased as long as there's unused capacity (not allocated to volumes) in the pool.
1
view
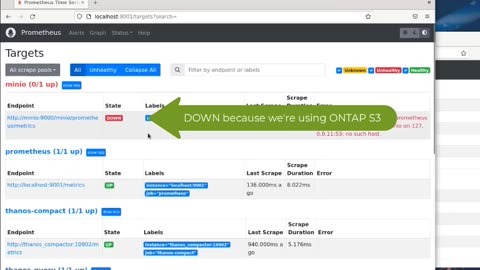
Thanos with NetApp S3 storage
This is mostly focused on Thanos with ONTAP S3, but there are other choices, namely StorageGRID and even MinIO with E-Series (or ONTAP).
12
views
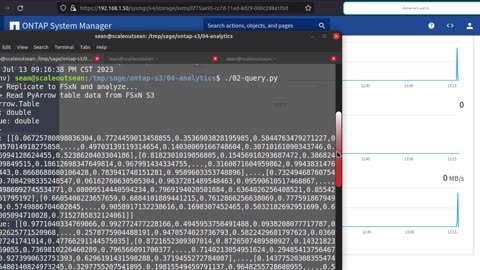
Simple multi-site or hybrid cloud workflow for S3 analytics with ONTAP S3
In this video I use the native S3 bucket created in the earlier video at
https://rumble.com/v32fmic-brief-walk-through-over-ontap-native-and-multi-protocol-s3-services.html
The idea is to show how one could organize multi-location ingress and processing:
- Site A generates or ingresses data via S3 or NFS (in the case of multi-protocol ONTAP S3 buckets)
- We use SnapMirror S3 to replicate to another ONTAP system such as AWS FSxN in the cloud. For multi-protocol buckets we could use SnapMirror (not SnapMirror S3!), CloudSync, rclone or some other utility
- Site B can read data using NFS (multi-protocol) or S3 - whichever works better. It is recommended to use the same config (either multi-protocol, or "pure" S3) on both sides to avoid incompatibility issues.
The video shows an example with native S3 buckets on both sides.
On-the-fly conversion from Parquet file to Panda dataframes is meant to show sometimes data doesn't even need to be copied off S3 to local disk to be converted, which is convenient as the clients don't even need to mount NFS.
The video is a bit short for so many steps, but you can check ONTAP S3-related and analytics-related solutions documentation for more comprehensive descriptions of such workflows.
8
views
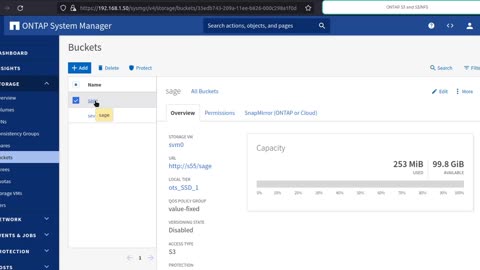
Brief walk-through over ONTAP "native" and multi-protocol S3 services
tldr;
- ONTAP "native" S3 has more complete AWS S3 API support, but is S3-only
- ONTAP "multiprotocol" S3 is S3 service that usually runs on NFS shares; it lets you combine NFS uploads/downloads with S3 PUTs/GETs, but its S3 API support is more limited because it's impossible to perfectly translate the differences between protocols
Users could run both, for different use cases and applications. Applications that use complex S3 API methods are less likely to work well on multi-protocol buckets.
6
views
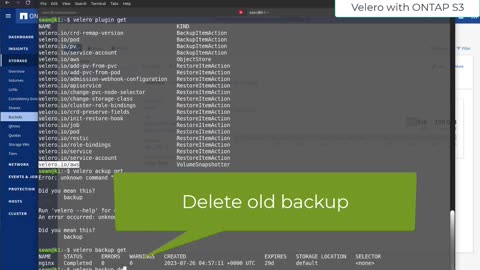
Velero with ONTAP S3 backup repository
tldr; Velero can use recent ONTAP's native S3 buckets for its AWS S3-compatible backup repo.
More:
https://scaleoutsean.github.io/2023/07/26/ontap-s3-as-velero-object-store.html
40
views
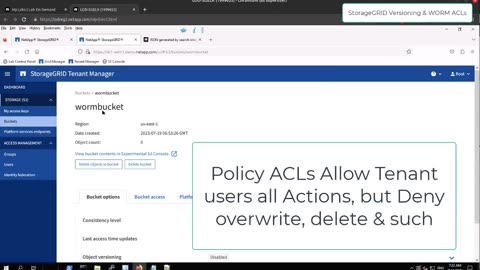
How versioning and WORM-like ACLs work on NetApp StorageGRID
Versioning is used to provide access to previous revisions of an object (e.g. GET object.mp3?v=2 gets revision #2 of the object). *If* users are allowed to overwrite objects but *not allowed* to delete old versions (not the default!), then objects practically become indelible.
But each revision is a copy that takes up disk space, so the benefit of versioning should be higher than its cost.
One popular feature used in conjunction with S3 versioning is S3 Object Lock with specified retention, which guarantees retention until a certain date, but unlocks and allows deletion of older objects - very useful for backups that need to be ransomware-resistant as long as they're needed.
But even without any of these tricks, the versioning feature protects files from accidental deletion or change, as you can always GET object.mp4?v=2 and re-upload it to recover from deleting the object or uploading a wrong revision 3.
Wondering about Object Lock with S3 versioning vs. legacy "Compliance"? See https://docs.netapp.com/us-en/storagegrid-117/ilm/managing-objects-with-s3-object-lock.html
"Software WORM" or ACLs-based WORM is simpler: it aims to prevent users from modifying (and hence also deleting) existing objects. To do that we craft a bucket policy ACL that prevents these requests to non-admin users. Obviously this isn't as robust, but it serves many purposes, including prevention from accidental modification or deletion of files, and unlike versioning, does not take extra storage space.
7
views
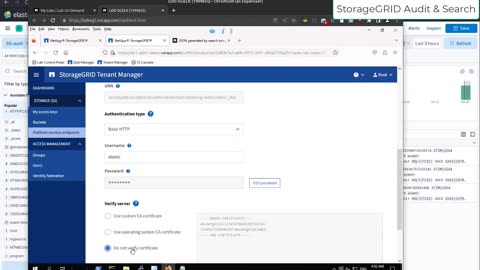
Use Elasticsearch to store NetApp StorageGRID audit log and build search index for objects
Prior to StorageGRID 11.6, StorageGRID couldn't forward audit log to external syslog servers. You had to copy it off the primary admin node, convert to JSON and upload.
https://github.com/scaleoutsean/storagegrid-audit-analysis
Version 11.6 has audit log forwarding.
This demo shows StorageGRID 11.7 and Elasticsearch 8.7.1:
a) Audit log forwarding: forwards audit log to Logstash which processes it and forwards to Elasticsearch
See https://docs.netapp.com/us-en/storagegrid-enable/tools-apps-guides/elk-instructions.html for more.
b) Platform services (search): configure StorageGRID to send event updates to Elasticsearch API endpoint. These updates are JSON files with system and object metadata, and allow us to search for various properties in Elasticsearch.
See https://docs.netapp.com/us-en/storagegrid-117/tenant/using-search-integration-service.html
12
views
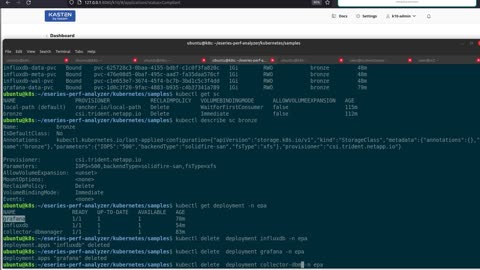
Use Kasten to backup and restore E-Series Performance Analyzer application
E-Series Performance Analyzer (EPA) is a collector that gathers NetApp NetApp E-Series storage array's metrics and events and stores them in InfluxDB. You can get it on Github.
This video shows backup & restore actions of using Kasten. EPA consists of two or more application containers, one Grafana and InfluxDB v1 instance.
- Config files
- Secrets
- Deployment
- Service
- PVC
More:
https://scaleoutsean.github.io/2023/02/10/backup-epa-data-on-kubernetes.html
5
views
KubeVirt with Trident, SolidFire and Kasten
KubeVirt is still a young and maturing product, but it's good enough for experimenting (it's just about to cross that line between frustration and experimentation).
This video shows how a Kubevirt VM's persistent volume (PVC) can be protected with storage snapshots, using NetApp Trident v23.01 with SolidFire 12.5.
https://scaleoutsean.github.io/2023/02/12/backup-restore-kubevirt-vms-with-solidfire-kasten-kubernetes.html
40
views
NetApp E-Series Performance Analyzer (EPA) v3.2.0 for Kubernetes
This fork of EPA aimed to separate E-Series collector container(s) from each other and from InfluxDB and Grafana, and that's been achieved in v3.2.0: now it's very easy to run EPA in containers using Docker, Docker Compose, Kubernetes or Nomad.
Docker Compose works very similarly - see
https://github.com/scaleoutsean/eseries-perf-analyzer
There's a video for Docker Compose using EPA v3.1.0 here on Rumble, but in v3.2.0 it's even simpler in v3.2.0 as there's no "make build" for collector containers. Anyway, just see the repo README.md.
FAQs:
https://github.com/scaleoutsean/eseries-perf-analyzer/blob/master/FAQ.md
Blog post for v3.2.0:
https://scaleoutsean.github.io/2023/01/14/eseries-performance-analyzer-container-orchestrator-kubernetes.html
18
views
Containerized NetApp Cloud Sync Data Broker
Something that isn't supported, but is possible: a containerized Data Broker from NetApp Cloud Sync v1.0.37.
More here:
https://scaleoutsean.github.io/2023/01/19/containerized-netapp-cloudsync.html
2
views
NetApp Cloud Sync API and Elasticsearch
Use the Cloud Sync API to improve your data synchronization and replication workflows.
More at:
https://scaleoutsean.github.io/2023/02/06/cloud-sync-elasticsearch.html
Cloud Sync API Bearer Tokens are valid 24h, which is why the token isn't masked.
8
views
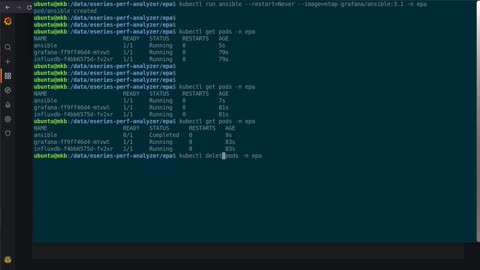
E-Series Performance Analyzer 3.1.0 on Kubernetes
Shows how to deploy and configure EPA 3.1.0 on Kubernetes.
18
views
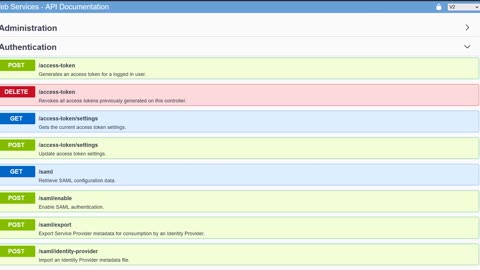
NetApp E-Series SANtricity API with JWT Bearer Tokens
Short demo on how to enable and use JWTs with SANtricity 11.70.4 or higher
20
views
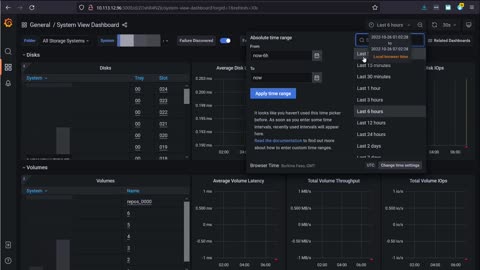
NetApp E-Series Performance Analyzer walk-through
Walk through E-Series Performance Analyzer 3.0.0
11
views
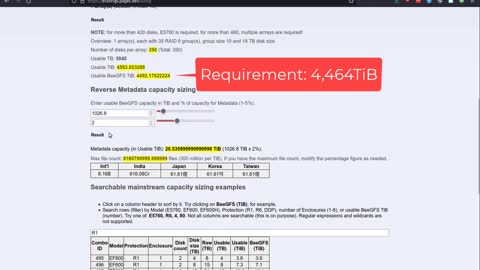
E-Series sizing for BeeGFS
I needed a sizer suitable for sizing E-Series for BeeGFS, so I built my own...
It takes me less than 60 seconds to create a capacity based sizing for probably 90% of requirements.
5
views
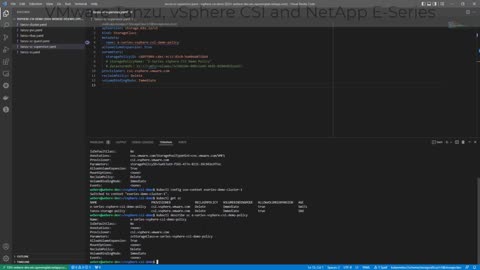
VMware Tanzu, vSphere CSI Plugin and NetApp E-Series Storage
This video shows the entire process of using NetApp E-Series arrays with VMware Tanzu with vSphere CSI plugin.
While this isn't a substitute for reading the official Tanzu and E-Series documentation, it takes you through the whole process in 10 minutes.
26
views

BeeGFS on ARM64 with BeeGFS CSI
This is an all-CLI video with a walk through of configuring BeeGFS CSI plugin for Kubernetes on ARM64 servers running Ubuntu 20.04 (AWS Graviton, in this particular case).
BeeGFS 7.3.0 is the first release with ARM64 support.
Some additional information is available at this link:
https://scaleoutsean.github.io/2022/04/30/beegfs-csi-on-arm64.html
5
views
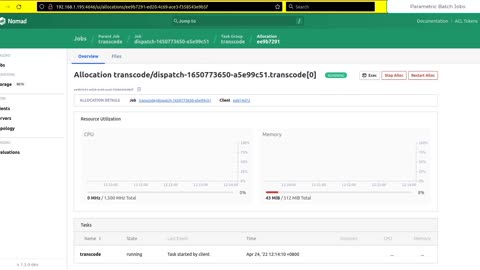
Scaling out IO-intensive parametrized jobs with Nomad and BeeGFS
I call them parametric and HashiCorp calls them parametrized. But in any case, when such jobs run they need plenty of IO bandwidth and parallel file systems still beat Object Stores by a large margin.
This video shows how we can scale such jobs with Nomad 1.3.0 with BeeGFS 7.3.0.
More here:
https://scaleoutsean.github.io/2022/04/24/nomad-batch-job-scale-out-parallel-filesystem-beegfs-e-netapp-series.html
1
view
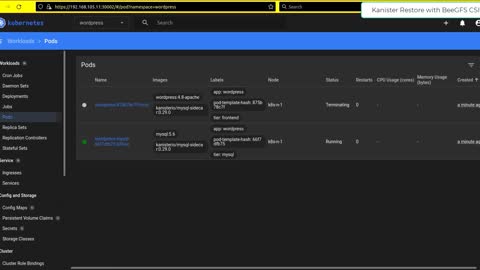
Kanister with BeeGFS CSI and E-Series
Demo of Kanister restore action with a database (MySQL) and flat files (Wordpress) on BeeGFS CSI-managed PVCs.
Details:
https://scaleoutsean.github.io/2022/04/13/backup-restore-beegfs-csi-pv-with-kanister-kasten.html
3
views
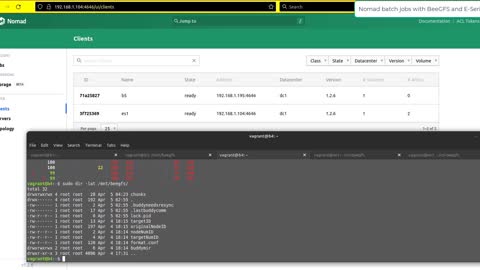
HashiCorp Nomad batch jobs with BeeGFS and NetApp E-Series
Two examples of scheduling IO-intensive jobs to client running BeeGFS parallel filesystem backed by E-Series storage.
- FIO
- Video conversion
Additional details:
https://scaleoutsean.github.io/2022/04/05/nomad-beegfs-eseries.html
1
view